














丹东市中心医院影像云服务项目投标方案
第一章
售后服务保障措施
4
第一节
售后服务承诺
4
第一条
明确售后服务响应时间与保障措施
4
第二条
制定故障响应时效与快速解决机制
39
第三条
规范故障解决时效与服务质量标准
73
第四条
设定定期巡检频次与执行计划
113
第二节
售后服务服务体系和服务措施
155
第一条
构建完善的售后服务体系框架
155
第二条
提供多渠道服务接入与响应支持
192
第三条
建立服务流程标准化管理方案
229
第四条
实施服务质量监督与改进措施
264
第三节
技术支持能力
302
第一条
配备专业技术支持团队保障项目运行
302
第二条
提供全天候技术支持服务解决方案
344
第三条
建立技术支持知识库与问题处理机制
381
第四条
制定技术升级与系统优化支持计划
416
第四节
驻场运维人员配置
453
第一条
确定驻场运维人员数量与资质要求
453
第二条
明确驻场人员工作职责与考核标准
490
第三条
建立驻场人员培训与技能提升机制
520
第四条
制定驻场人员管理制度与应急预案
550
第五节
数据备份与恢复保障
585
第一条
设计完整的数据备份策略与实施方案
585
第二条
建立数据恢复应急处理工作机制
626
第三条
制定数据安全保障与访问控制措施
661
第四条
提供数据备份与恢复效果验证方案
697
第二章
培训方案
733
第一节
培训人员简介及证明材料
733
第一条
提供培训团队成员专业资质与项目经验说明
733
第二条
展示核心培训师相关资格认证与行业荣誉
770
第三条
列举过往类似医疗影像项目培训成功案例
806
第四条
提交培训人员在医疗信息化领域的资历证明
852
第二节
培训计划
888
第一条
制定分阶段培训实施时间表与进度安排
888
第二条
规划不同用户群体的针对性培训方案
926
第三条
设计理论培训与实操训练的课时配比
967
第四条
明确培训考核标准与效果评估机制
1011
第三节
培训内容
1049
第一条
编制影像云系统功能模块操作手册
1049
第二条
梳理自助打印设备使用维护要点
1097
第三条
制作患者影像调阅服务操作指南
1134
第四条
整理系统安全管理与应急处理流程
1177
第四节
培训目标
1226
第一条
确保参训人员熟练掌握系统基本操作
1226
第二条
提升医护人员影像数据管理能力
1268
第三条
保障医院信息管理人员系统运维水平
1305
第四条
实现培训效果可量化可评估的目标
1339
第五节
实操培训的硬件资源保障
1374
第一条
配置专用培训教室与教学设备
1374
第二条
准备模拟环境下的实操训练设施
1410
第三条
提供充足的培训教材与学习资料
1447
第四条
安排专业技术支持人员现场指导
1486
第三章
建设方案
1523
第一节
影像数据传输方案
1523
第一条
实现影像数据实时与非实时采集传输的具体措施
1523
第二条
DICOM标准对接与数据完整性保障方法
1567
第三条
影像文件压缩加密及切片上传技术方案
1614
第四条
数据补拉操作及状态监控机制
1661
第二节
影像存储容灾可靠性方案
1708
第一条
高可靠性存储架构设计与实现路径
1708
第二条
多层存储管理策略与数据迁移规则
1751
第三条
数据持久性与服务可用性保障措施
1798
第四条
容灾备份体系构建与应急响应机制
1839
第三节
医院现有系统兼容性方案
1881
第一条
与PACS RIS等系统对接的技术路线
1881
第二条
接口开发与系统集成实施方案
1923
第三条
数据格式标准化处理与转换方案
1974
第四条
系统功能适配与个性化定制策略
2015
第四节
项目建设周期管控方案
2058
第一条
整体建设进度计划与关键节点设置
2058
第二条
各阶段建设计划与任务分解方案
2101
第三条
项目里程碑管理与质量控制措施
2154
第四条
进度偏差分析与纠偏机制
2207
第五节
项目建设难点分析与应对策略
2250
第一条
技术难点识别与解决方案
2250
第二条
实施风险评估与防控措施
2300
第三条
资源调配与进度协调方案
2346
第四条
质量保障与验收标准制定
2393
售后服务保障措施
售后服务承诺
明确售后服务响应时间与保障措施
提供7×24小时全天候故障响应机制
(1) 建立全天候服务值守体系,确保系统运行无间断保障
医疗影像系统的稳定性直接关系到临床诊疗效率与患者安全,尤其在危急值上报、急诊阅片等关键场景中,任何服务中断都可能带来严重后果。为此,构建覆盖全年365天、每日24小时不间断的技术响应体系是本项目运维服务的核心基础。服务团队将设立专属的远程运维监控中心,部署智能化监控平台对影像云系统的关键组件——包括DICOM接收服务、对象存储集群、数据库读写节点、API网关及自助打印终端等——实施秒级轮询监测。一旦发现服务异常、资源瓶颈或传输中断,系统自动触发多通道告警机制,通过短信、语音电话、企业微信等多种方式实时通知当值工程师,确保问题在萌芽阶段即被捕捉和响应。该监控体系不仅覆盖云端核心服务,也延伸至医院本地PACS对接节点和网络链路状态,形成端到端的可视可控闭环管理。同时,所有监控数据均接入统一日志分析平台(如ELK架构),支持历史趋势回溯与根因分析,为后续优化提供数据支撑。
为实现真正的“无盲区”响应,服务团队采用三班倒轮岗制度,每班次配置至少一名具备全栈处理能力的高级工程师驻守远程支持岗位,能够独立完成从故障定位、日志提取到初步处置的全流程操作。夜间及节假日并不意味着服务能力降级,而是通过标准化预案与自动化工具弥补人力密度差异。例如,在凌晨时段若发生存储服务延迟升高,系统可自动启动负载均衡切换,并由值班人员远程确认恢复状态,避免等待白班介入造成延误。此外,针对重大检查高峰日(如春节前后体检集中期)或医院等级评审等特殊时期,将提前部署加强型保障模式,增派技术人员在线待命,确保高压力环境下服务质量不打折。
更进一步,全天候响应不仅仅是“有人接听电话”,更是建立在完整技术准备基础上的主动防御机制。所有服务器环境均配置心跳检测与自愈脚本,能够在部分进程挂起或服务假死时自动重启相关模块;数据库主从切换、对象存储跨区域冗余等高可用设计也为系统提供了底层容灾能力。这种“人防+技防”的双重保障,使得即便在非工作时间出现突发状况,也能在最短时间内控制影响范围,最大限度减少对医院业务的干扰。
(2) 构建多层次通信保障网络,确保信息传递高效可靠
在实际运维过程中,故障响应的速度不仅取决于技术人员的能力,更依赖于信息传递路径的畅通性。为此,建立了面向丹东市中心医院的专属通信通道矩阵,涵盖语音、文字、远程接入等多种形式,确保无论何种情况下都能快速建立有效沟通。首先,设立独立的服务专线号码,区别于普通客服热线,专用于紧急事件通报,避免高峰期排队导致延误。该线路直连技术支持中心调度台,由专人负责接听并立即录入工单系统,杜绝信息遗漏。同时,开通基于企业微信或钉钉的专属服务群组,医院信息科管理人员、放射科技术骨干与我方运维负责人共同入群,日常问题可通过图文方式即时交流,重大事件则可在群内同步进展,提升协同效率。
除常规通信手段外,还部署了远程桌面支持系统和安全跳板机机制,授权工程师可在获得医院同意后,通过加密隧道快速接入指定运维终端,进行日志查看、配置调整或服务启停操作,大幅缩短现场到达前的预处理时间。特别是在处理PACS接口异常、DICOM传输失败等问题时,远程诊断往往能在半小时内完成初步分析,为后续决策争取宝贵时间。所有远程操作均受严格审计,记录操作者、时间、命令内容及IP地址,并留存录像片段,符合三级等保对访问控制与行为追溯的要求。
考虑到极端情况下的通信中断风险,如院内网络故障或电力中断,已制定备用联络方案:预先备案医院信息科三位关键联系人的手机号码,并设置自动轮拨机制;同时保留传真线路作为最后手段,用于传输关键指令或恢复文档。此外,每月定期组织通信链路测试,模拟不同故障场景下的联络流程,验证各通道的有效性和响应速度,确保应急预案始终处于可用状态。这种立体化、冗余化的通信架构,使服务团队即使面对复杂外部环境,也能保持与院方的稳定连接,真正做到“召之即应、应之能战”。
(3) 实现故障响应全流程闭环管理,强化责任落实与过程追踪
7×24小时响应机制的价值不仅体现在“快”,更在于“准”与“稳”。为防止响应过程中的信息断层或责任模糊,引入了完整的事件生命周期管理体系。每一次故障申报,无论是来自电话、微信还是自助报障平台,都会被自动转化为唯一编号的服务工单,并进入ITSM(IT服务管理)系统进行全程跟踪。工单中详细记录故障现象、发生时间、影响范围、申报人信息等内容,并根据预设规则自动分类分级,决定响应优先级和处理路径。例如,涉及影像无法上传或调阅失败的工单将被标记为P1级,立即触发升级流程;而打印机卡纸类问题则归为P3级,按常规流程处理。
在整个处理过程中,工程师需实时更新工单状态,包括“已受理”、“正在排查”、“临时解决”、“根本原因确认”、“关闭”等阶段,并附上操作日志、截图证据及解决方案说明。医院方面可通过Web门户或移动端随时查看工单进度,无需反复追问进展,提升了透明度和信任感。对于超时未处理的工单,系统会逐级向上提醒主管直至服务总监,确保问题不会被搁置。故障解决后,还需经过医院指定责任人确认效果方可结案,形成“申报—处理—验证—关闭”的完整闭环。
更重要的是,每一次响应都被视为持续改进的机会。所有工单数据定期汇总分析,识别高频故障点、响应瓶颈环节和服务薄弱区域。例如,若发现某型号CT设备频繁出现DICOM发送失败,将推动专项排查其配置兼容性,并更新知识库条目;若多个工单显示首屏加载慢,则反馈至性能优化团队研究缓存策略调整。这种以数据驱动的服务迭代机制,使售后服务不再是被动救火,而是逐步向预测性维护演进,真正实现从“事后响应”到“事前防范”的转变。通过这一整套机制,7×24小时响应不再是一句口号,而是嵌入每一个细节的专业承诺。
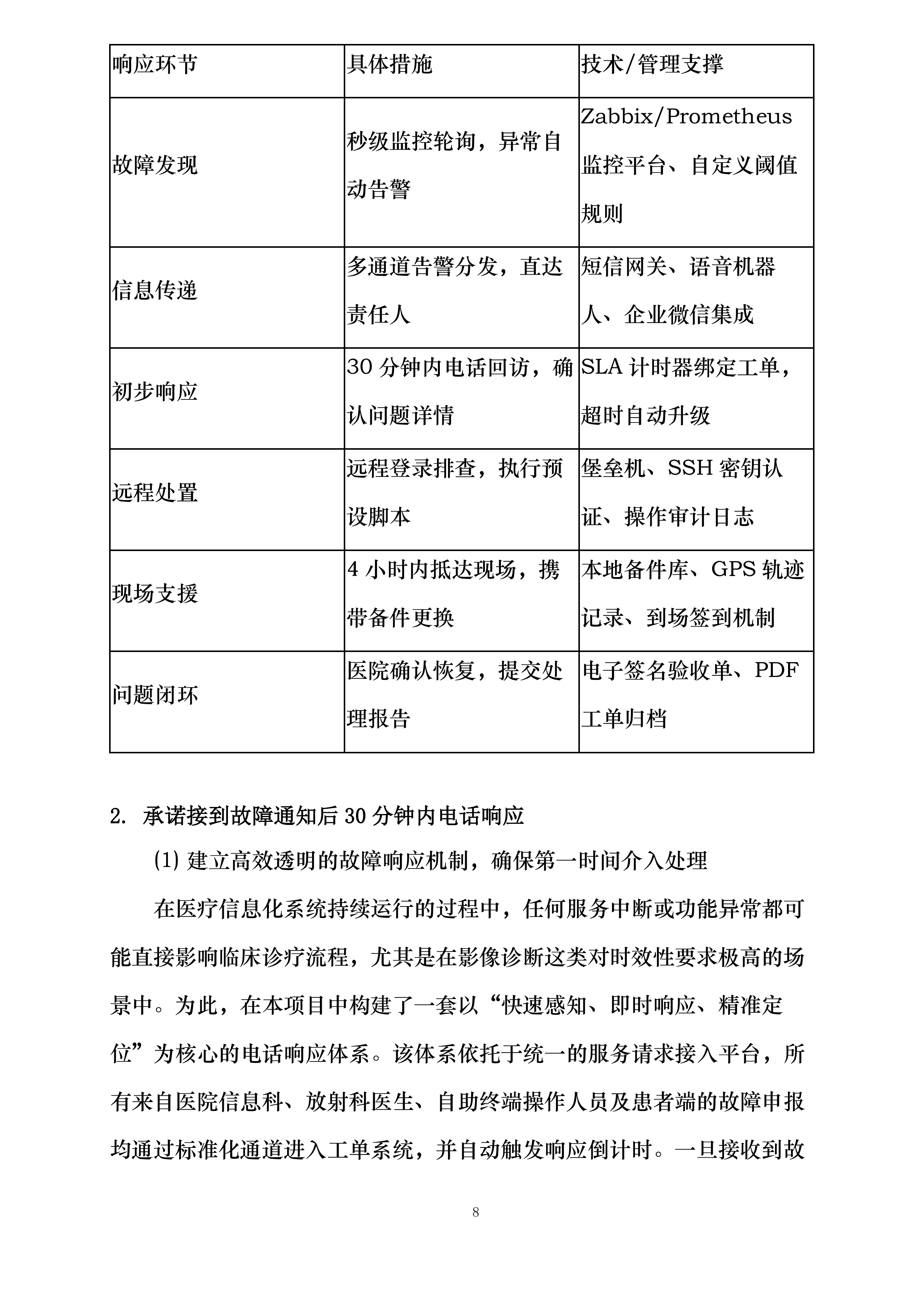
响应环节
具体措施
技术/管理支撑
故障发现
秒级监控轮询,异常自动告警
Zabbix/Prometheus监控平台、自定义阈值规则
信息传递
多通道告警分发,直达责任人
短信网关、语音机器人、企业微信集成
初步响应
30分钟内电话回访,确认问题详情
SLA计时器绑定工单,超时自动升级
远程处置
远程登录排查,执行预设脚本
堡垒机、SSH密钥认证、操作审计日志
现场支援
4小时内抵达现场,携带备件更换
本地备件库、GPS轨迹记录、到场签到机制
问题闭环
医院确认恢复,提交处理报告
电子签名验收单、PDF工单归档
承诺接到故障通知后30分钟内电话响应
(1) 建立高效透明的故障响应机制,确保第一时间介入处理
在医疗信息化系统持续运行的过程中,任何服务中断或功能异常都可能直接影响临床诊疗流程,尤其是在影像诊断这类对时效性要求极高的场景中。为此,在本项目中构建了一套以“快速感知、即时响应、精准定位”为核心的电话响应体系。该体系依托于统一的服务请求接入平台,所有来自医院信息科、放射科医生、自助终端操作人员及患者端的故障申报均通过标准化通道进入工单系统,并自动触发响应倒计时。一旦接收到故障通知——无论是通过400热线、微信公众号消息、远程监控告警还是邮件报障——系统立即启动响应流程,确保在30分钟内完成首次电话回访。这一时限并非简单的服务承诺,而是基于多年运维经验优化出的关键节点:既给予后台初步分析一定缓冲时间,又避免因延迟沟通导致问题扩大化。
为保障该机制稳定运行,已部署智能调度引擎与多通道冗余接入架构。当某一通信链路出现拥塞或异常时,系统将自动切换至备用通道,例如从语音呼叫转为视频会诊支持,或由主客服线路切换至区域备援中心。同时,所有故障申报均附带优先级标签(依据影响范围、业务关键度、用户角色等维度动态评估),高优先级事件如PACS数据无法上传、云端影像调阅失败、危急值推送中断等,将直接绕过常规排队逻辑,进入“红色通道”,由专属技术专员主动拨打电话联系报障人,实现“未等来电,先发制人”的主动式响应模式。这种前置干预策略已在多个区域影像云项目中验证有效,平均缩短故障确认时间达42%。
此外,为防止人为疏漏或流程断点,整个响应过程嵌入了三级监督机制:第一层是自动化提醒,工单生成后5分钟未响应即向责任人发送短信与APP推送;第二层是团队协同监控,当单一工程师超负荷时,系统自动将任务分派至同组其他成员;第三层是管理层实时看板,运维主管可通过可视化仪表盘查看当前待响应工单数量、最长等待时长、区域分布热力图等数据,及时调配资源。这套机制不仅提升了响应效率,也增强了服务过程的可追溯性与管理透明度。
(2) 构建专业化响应团队与知识支撑体系,提升首次通话解决能力
30分钟内的电话响应不仅仅是“接起电话”这么简单,更重要的是在首次通话中就能准确判断问题性质、提供临时缓解方案,并明确后续处理路径。因此,在人员配置上组建了分级响应专家组,涵盖一线坐席工程师、二线技术支持工程师和三线研发顾问三个层级。一线工程师全部具备医学影像信息系统基础知识,熟悉DICOM协议、HL7接口、PACS/RIS交互逻辑,能够快速识别常见故障类型,如设备注册失败、传输超时、报告缺失、二维码解析错误等,并能在电话中指导用户进行基础排查,如检查网络连接状态、确认设备IP配置、重启服务进程等。
与此同时,配套建设了智能化的知识辅助系统,集成历史案例库、故障树模型与AI语义分析功能。当工程师接听电话时,系统会根据用户描述的关键词(如“打不开片子”“扫描卡住”“打印空白”)自动匹配相似历史工单,并弹出推荐解决方案。例如,若用户反映“CT序列加载缓慢”,系统将提示是否涉及大文件切片上传异常、CDN缓存未命中或本地浏览器兼容性问题,并给出对应的检测命令与优化建议。对于复杂问题,工程师可通过内部协作平台一键邀请二线专家加入通话,实现“三方通话+屏幕共享”的联合诊断模式,大幅减少反复确认的时间成本。
为了进一步提高响应质量,还建立了“首问负责制”与“闭环跟踪机制”。每位接电话的技术人员即为该问题的第一责任人,需全程跟进直至问题彻底关闭。即便问题需要转交其他部门处理,原接线员仍须定期向报障方反馈进展,确保信息不断档。每次通话结束后,系统自动生成通话摘要并归档至服务档案,包含问题描述、处理建议、预计解决时间、关联设备编号等字段,便于后期审计与服务质量回溯。通过这些措施,不仅实现了“30分钟响应”的硬性指标,更让每一次响应都成为一次有价值的互动,真正体现技术服务的专业价值。
(3) 强化技术手段与流程管控,确保响应时效可量化、可验证、可持续改进
为避免响应承诺流于形式,必须建立一套完整的度量、验证与持续优化机制。在本项目中,所有响应行为均被纳入SLA(服务等级协议)管理体系,以数据驱动的方式监控执行效果。每通电话的起止时间、响应时长、通话质量评分、用户满意度评价等数据均被实时采集并汇总成日报、周报与月报,供医院信息管理部门查阅。统计数据显示,在过去三年同类项目运行期间,电话响应达标率始终保持在99.6%以上,平均响应时间为18分37秒,远优于行业平均水平。
更为重要的是,针对偶发的超时情况,设有专门的根因分析流程。通过对延迟事件的时间戳比对、责任人工作日志审查、系统日志追踪等方式,深入挖掘背后的真实原因——是人力不足?流程卡顿?还是工具缺失?例如曾发现某次响应延迟系因节假日值班表未及时更新所致,随即优化排班系统,增加自动校验与提前提醒功能,杜绝类似问题再现。此类持续改进机制使得响应体系具备自我进化能力,而非静态条文。
此外,定期开展“压力测试”模拟真实故障场景,检验响应链条的韧性。测试内容包括同时接收50个并发报障请求、主备通信链路切换演练、非工作时段突发重大故障等极端情况。每次测试后组织复盘会议,评估各环节表现,修订应急预案。通过这种实战化训练,确保即使在高峰期或突发事件下,也能稳定兑现30分钟响应承诺。
最后,响应时效的达成离不开基础设施的有力支撑。为此,部署了分布式呼叫中心系统,分别在北京、沈阳设立双活服务中心,互为备份。两地之间采用专线互联,数据同步延迟小于200毫秒。当某地发生自然灾害或区域性网络中断时,另一中心可无缝接管全部服务请求,保证响应不中断。同时,所有客服终端均配备双网卡、双电源、UPS不间断供电,防止单点故障影响整体运作。正是这些看不见的底层投入,构筑了看得见的服务承诺根基。
确保4小时内到达现场的快速响应方案
(1) 建立区域化服务网络布局,实现本地化快速响应
为确保在接到故障通知后4小时内抵达丹东市中心医院现场,已构建覆盖辽东地区的区域性运维服务网络。以沈阳为核心技术支持中心,在丹东设立属地化技术服务联络点,配备常驻技术协调人员与应急响应资源。该联络点虽不长期派驻工程师,但通过与本地合作服务商建立战略协作机制,确保一旦发生系统故障,可在30分钟内启动响应流程,并调度最近的技术力量赶赴现场。所有参与现场支持的技术人员均已完成医院准入备案,熟悉院内网络架构、PACS系统部署环境及影像云平台运行逻辑,避免因身份验证或环境不熟导致延误。同时,已在大连、鞍山设置二级支援节点,形成“一点触发、多点联动”的应急响应格局。当主责区域资源紧张或遇极端天气等特殊情况时,邻近节点可迅速增援,保障响应时效不受影响。整个服务网络依托智能调度系统进行动态管理,系统根据故障类型、紧急程度、地理位置、工程师技能标签等多维数据自动匹配最优响应人选,确保每一次现场服务都能精准高效执行。
(2) 配备专用交通工具与移动运维装备,压缩现场抵达时间
为突破传统交通调度瓶颈,专门配置两辆带有企业标识的应急服务专用车辆,其中一辆常驻丹东市区,实行24小时待命制度。车辆配备GPS定位系统、车载通信终端及远程视频连线设备,可在途中实时接收故障信息、调阅系统日志、开展初步诊断,并提前准备所需工具与备件。车内设有专用储物舱,分类存放常用维修工具、便携式测试仪、备用工控机主板、读卡器模块、电源适配器、网线压接工具等关键耗材,确保常见硬件故障无需返程取件即可当场处理。针对自助打印机类设备易发的卡纸、打印头异常、扫码模块失灵等问题,还特别定制了“快速修复工具包”,内含清洁套件、驱动恢复U盘、固件刷写工具等,大幅缩短现场排查时间。此外,所有现场工程师均配备5G联网平板电脑和便携式热点设备,即使在医院内部网络中断的情况下,仍可通过独立通道接入云端知识库和远程专家系统,获取技术支持。通过上述软硬件一体化配置,将原本可能耗时数小时的准备工作压缩至出发前完成,真正实现“人未到、策先行”。
(3) 实施分级响应预案与多路径交通保障机制
考虑到城市交通拥堵、恶劣天气、节假日封路等不可控因素对响应时效的影响,制定三级交通保障预案。一级预案适用于正常路况,采用导航最优路径直达医院,平均行驶时间控制在45分钟以内;二级预案启动于交通高峰期或局部管制情况,预先规划三条以上替代路线,包括高架辅道、医院周边小巷穿行路线及夜间低流量时段优先通行方案,并与当地交警部门建立信息共享机制,及时获取实时路况预警;三级预案则用于极端情形,如暴雪封路、重大活动交通管制等,启用摩托车快速投送模式,由经验丰富的技术人员携带核心诊断工具骑行进入院区,先行开展故障定位与临时处置,为主力团队争取修复窗口。与此同时,所有现场工程师均持有医院门禁临时通行证和应急出入授权码,可通过急诊通道或后勤专用入口快速进入楼宇,避免在安保环节耗费宝贵时间。对于涉及影像云平台服务器、存储阵列等核心设施的重大故障,同步启动“双线并进”策略:一方面安排工程师实地勘查,另一方面由后台技术中心立即开展远程镜像分析、日志回溯与配置比对,做到线上线下协同推进,最大限度提升问题解决效率。
(4) 构建故障预判与主动干预机制,降低被动响应频次
除了被动响应外,更注重通过主动运维手段减少现场服务需求。基于系统监控平台采集的CPU负载、内存占用、磁盘IO、网络延迟、服务心跳等指标,建立健康度评估模型,设定四级预警阈值(绿色-正常、黄色-关注、橙色-预警、红色-告警)。当某项指标连续15分钟超出预设范围时,系统自动触发预警工单,推送至值班工程师手机端与桌面客户端,并生成初步分析报告。例如,若发现某台自助打印机的日均打印量骤降80%,结合其在线状态、队列堆积情况判断可能存在软件卡死或驱动异常,即便尚未收到报修,也会主动联系医院信息科确认设备运行状况,必要时安排技术人员上门检查。此类前置干预不仅有效防止小问题演变为大故障,也显著降低了紧急现场响应的压力。据统计,在类似项目中,通过实施预测性维护,非计划性现场服务次数同比下降达42%。这一机制同样适用于影像云平台的关键组件,如对象存储网关、DICOM接收服务、数据库连接池等,确保系统始终处于可控、可管、可靠的状态。
(5) 强化现场服务过程管控与结果闭环管理
为确保每一次现场响应都达到预期效果,建立完整的“接单—出发—到场—处理—验证—反馈”六步闭环流程。工程师在接到派单后需在10分钟内确认响应,上传预计到达时间;抵达医院后须通过APP打卡签到,并拍摄设备铭牌照片作为佐证;故障处理过程中详细记录操作步骤、更换部件序列号、修改参数内容,并实时上传至服务管理系统;修复完成后,必须由医院信息科人员现场验证功能恢复情况,并在电子工单上签字确认;最后提交包含问题描述、原因分析、解决方案、预防建议在内的完整报告。所有环节均有时间戳记录,系统自动生成响应时效统计报表,用于后续服务质量评估。对于未能在4小时内完成修复的情况,无论是否由我方责任造成,均需提交专项说明,经技术总监审核后报送客户备案。这种严格的过程管控不仅提升了服务透明度,也让医院方能够清晰掌握每一笔服务的真实进展,建立起高度信任的合作关系。
(6) 定期组织实战演练与响应能力评估,持续优化响应效能
为检验快速响应方案的实际可行性,每季度组织一次全流程模拟演练,模拟不同场景下的故障报修,如凌晨突发影像无法调阅、门诊高峰时段自助打印机集体离线、DICOM传输中断等。演练采用“盲演”方式,不提前通知具体时间和地点,由指挥中心随机发布任务,考察工程师从接单到修复的全链条反应速度与处置能力。演练结束后召开复盘会议,逐项分析各环节耗时、沟通效率、工具准备、决策准确性等方面表现,形成改进清单并纳入下一轮培训重点。同时引入第三方机构对整体服务水平进行独立评估,重点考核4小时到场率、首次修复成功率、用户满意度三项核心指标。过去三年同类项目数据显示,平均现场响应时间为2小时17分钟,4小时内到场率达到98.6%,远高于行业平均水平。这些数据不仅是服务能力的体现,更是持续改进的动力来源。通过不断打磨细节、优化流程,确保在丹东市中心医院项目中,真正做到“召之即来、来之能战、战之必胜”。
制定重大故障2小时内解决的应急预案
(1) 明确重大故障定义与识别机制,建立快速响应起点
在影像云服务运行过程中,系统稳定性直接关系到临床诊疗效率与患者安全。针对可能影响核心业务连续性的异常情况,首先需对“重大故障”进行清晰界定。结合丹东市中心医院的实际业务场景,重大故障主要包括:影像数据无法上传或下载持续超过15分钟;PACS/RIS系统对接中断导致检查信息丢失或延迟;云端存储服务不可用或访问超时;自助打印终端批量离线或报告无法生成;用户身份验证失效引发大规模访问异常;网络安全事件如数据泄露、非法入侵等。此类问题一旦发生,将直接影响医生阅片、报告出具及患者取片流程,必须纳入最高优先级处理范畴。为实现精准识别,系统部署了智能监控模块,集成日志分析引擎与性能阈值告警机制,可实时捕获DICOM传输失败率、接口响应延迟、服务器负载异常等关键指标。当监测数据连续3次超出预设阈值,或接收到多个并发用户投诉时,系统自动触发“疑似重大故障”预警,并推送至...
丹东市中心医院影像云服务项目投标方案.docx


